You might have heard that our local paper isn't what it used to be. It's hard to describe how jarring it has been to watch its decline. I don't have any close friends there but I've been lucky enough to meet or know several staffers there over the years and I can't imagine how it's been for them.
Sadly, it's not something worth paying for any longer, so we've unsubscribed.
That leaves me without a local paper. And reaching for the ol' feed reader. It works, as expected, but it's not quiiiiite what I want.
I didn't know that Terry Godier was working on Current when I read Terry's post on Phantom Obligation a few weeks ago. Aside from a very slick degrading-to-ascii rendering of diagrams piece which really stood out, I agreed fully with their problem statement that shaping a news reader like a set of growing inboxes isn't the right fit. There has been lots of praise for Current since its release, and I bet it's great, but I haven't tried it yet, because I'm not looking for a river.
I'm looking for a newspaper.
I love print newspapers. I loved them before I got to work on projects like Chronicling America and loved them even more after. We used to take the local paper daily, FT on Saturdays, and NYT on Sundays. Then a while back (you can guess the timeline, no need to replay it) we dropped the local print edition, switching to only online. Now that's gone.
But I need local news. I live here, and I want a city desk and weather and news about shows and exhibits and news of crazy snow mounds and book reviews. And sports! I love sports, and really enjoy following beat and opinion writers and looking forward to their takes on big games or trades and occasional features that help me get to know the players I root for and against better.
You can get all this with a feed reader - there's so much good stuff out there! - but it doesn't feel like a newspaper.
I want to open something with real local awareness and see a mix of big stories at different geopolitical scales mixed in with a good local section and an arts section and on and on. And I have another set of "requirements", for lack of a better word.
- Track far more feeds than I could possibly ever read serially to find good stuff from a wide range of sources
- Track a diversity of opinions - or at least a little wider than my typical well-circumscribed worldview - to be challenged to rethink things
- Track overlapping sources and look at different angles on the same story
- Keep a living discovery component that pulls in examples from new feeds I didn't already track so it's easy to expand the range of voices coming in
I want to track way more stuff than most people can but with a coherence and clarity that feels like the wise editorial staff of a stalwart paper has made thoughtful choices that fit my brain, sectioning up major news stories and a variety of categories of stories that I'm probably going to be interested in, even if I never read them all.
I also want to be able to find something new and realize I want to know more and then trace backward to see prior posts about the same thing from a variety of sources.
Okay, so now what?
My professional training and experience are in information science and data science, so naturally, my reaction to all this is to build a news service. Sort of.
NetNewsWire has been around forever and works great, so I'm using it as my stand-in reader and collector. I keep adding stuff to it. There's so much good and interesting writing out there! For years I was locked into the well-known loop of checking the same 5-7 sites every day, all the time, and it gnawed at me for ages but now I can actually do something about it. And, in a way, it feels like I have to, considering the number one item on that site list basically doesn't exist any more.
So I have an experimental repo with a messy pile of specs for experiments and bits of infrastructure plans for folding, spindling, and mutilating the data coming in through NNW to see if I can start to get to a "newspaper" that I want to read every day. It's a mess. Really. It's a private repo on github because I wouldn't expect anyone to understand it. I don't think I understand it. But there are a lot of interesting pieces in there already.
For one thing, the new tools make it ridiculously easy to try stuff, to explore a design and feature and data space to see if you can make an idea work. And when you try stuff, you then need to evaluate it, and it's also ridiculously easy to build evaluation tools that feed back into the process. Here's a taste of a few of those. None of this is fully baked.
Named entity recognition
One of the ongoing experiments involves NER. Can we do this well enough on arbitrary feed content to build features around it? I'm not sure, but I'm trying. The following image is a little squeezed and throws off the alignment of the assessment "buttons", but imagine they look a lot neater, enough that it's an easy tool to assess lots of extracted names of people, places, and organizations quickly. Can some popular libraries do this well? Can a local LLM do it better and also fast enough on my consumer laptop? What does the data model need to look like, and can it be good enough often enough to hang features on? This entity canonicalization assessment tool helps me start to answer some of those questions.
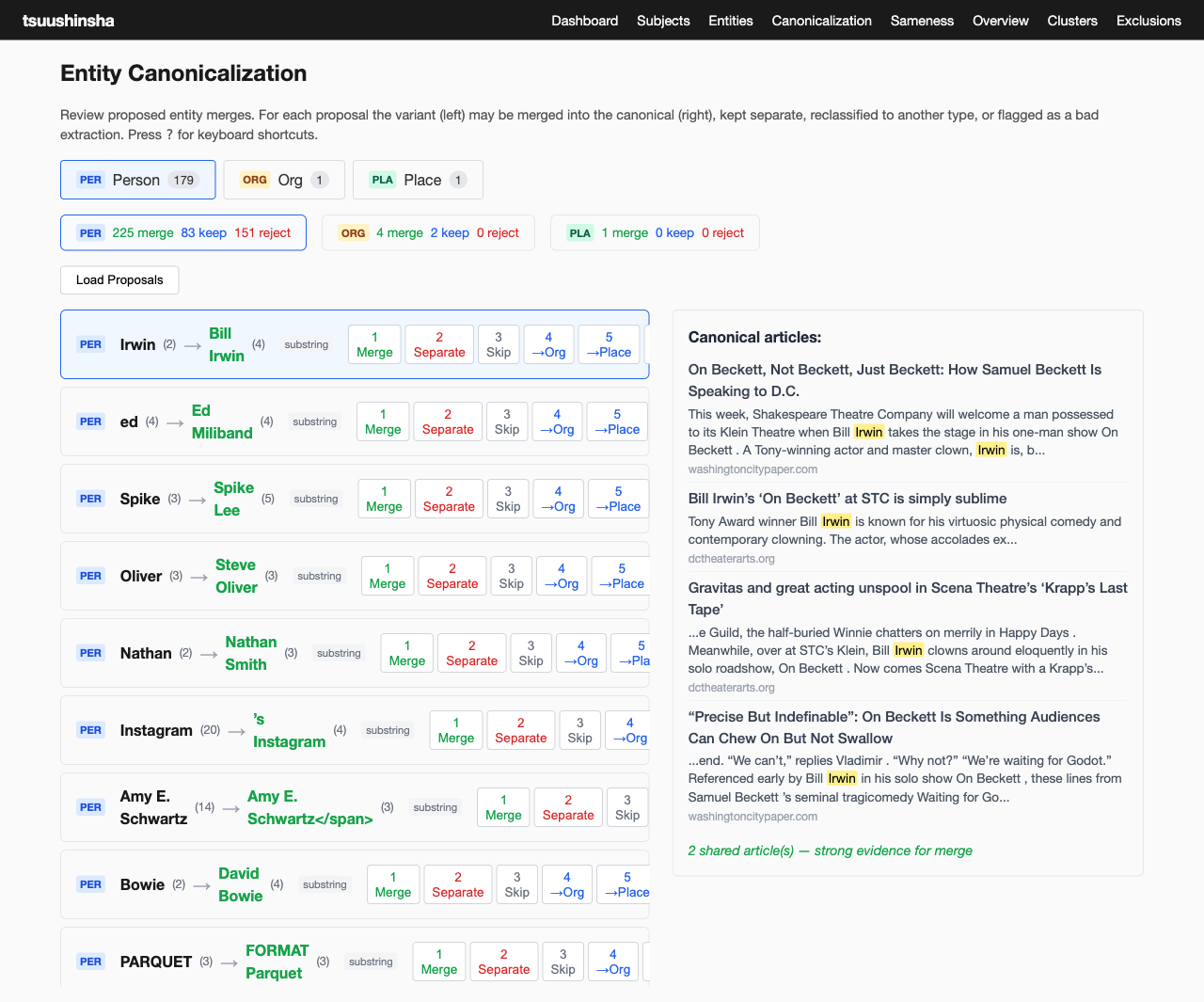
Article sameness
Another key area I need some traction on to make my weird vision come together is a good handle on finding articles that are about the same thing. Either duplicates, or linklogs posting the same external post, or multiple news stories about the same event, or many stories related to but not strictly about the same event. This isn't a new problem, but I'm trying to come up with a banded sameness factor using embeddings that is fast to compute and easy to build around. The image below shows evaluating the sameness assessments the experimental code has generated.
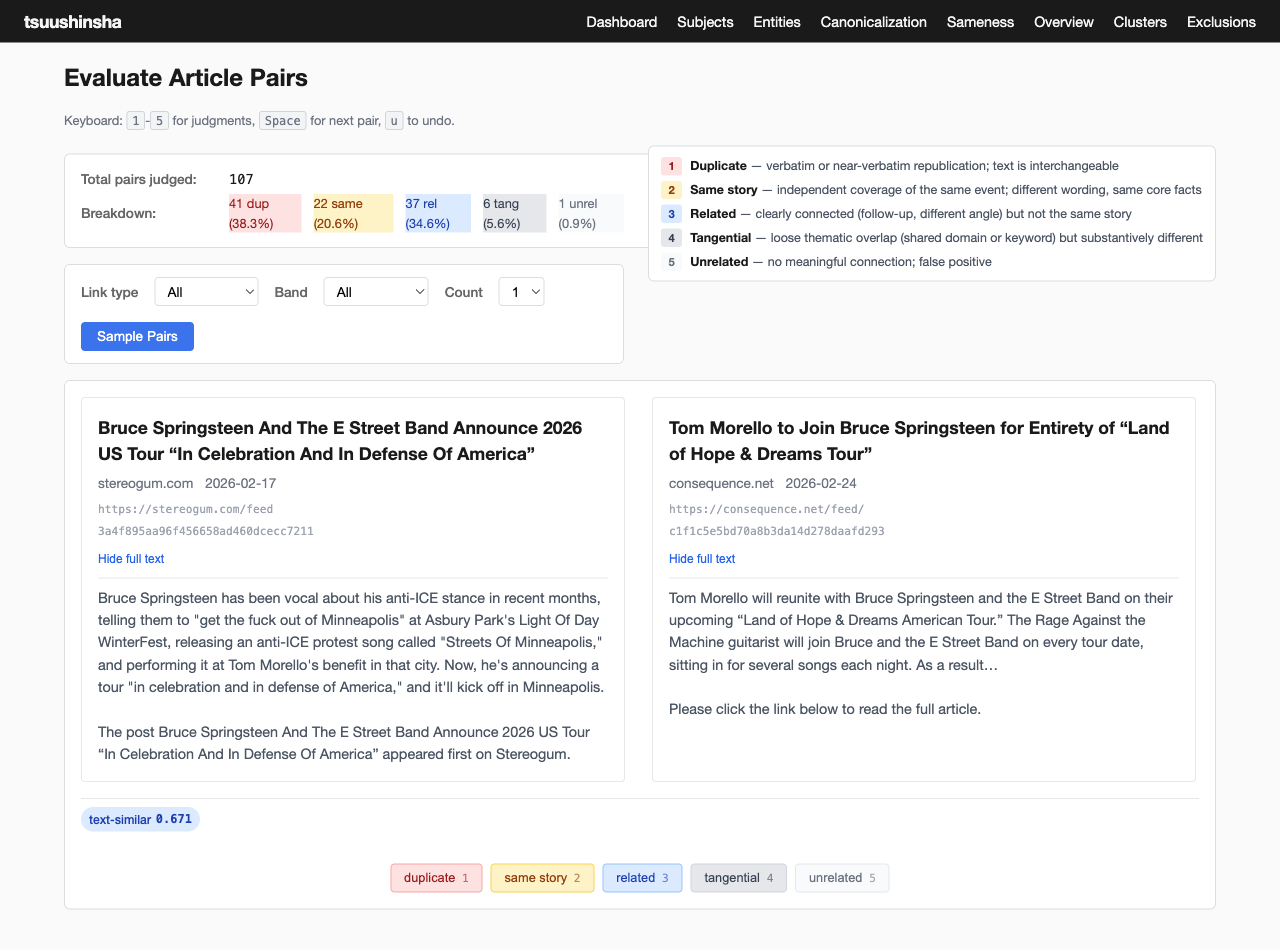
Story clusters
This last screenshot shows an attempt to assess designation of story clusters with tagged facets or threads to make it easy to find different ways into and through a story. It feels promising. It's another case where I have to find a sweet spot between local llm quality and fast/cheap computability if this is going to work at the content scale I'm aiming for. Right now, that's about 300 feeds grouped into 10-12 categories (roughly akin to newspaper sections we're all familiar with), and I would hope that if this goes well that feed count will double or triple before long. But that's already something like 1k new posts coming in every day, and you just can't ask a local llm to churn through all that and update clusters on a macbook air, however neat the M processors are (which is pretty neat, but not magical).
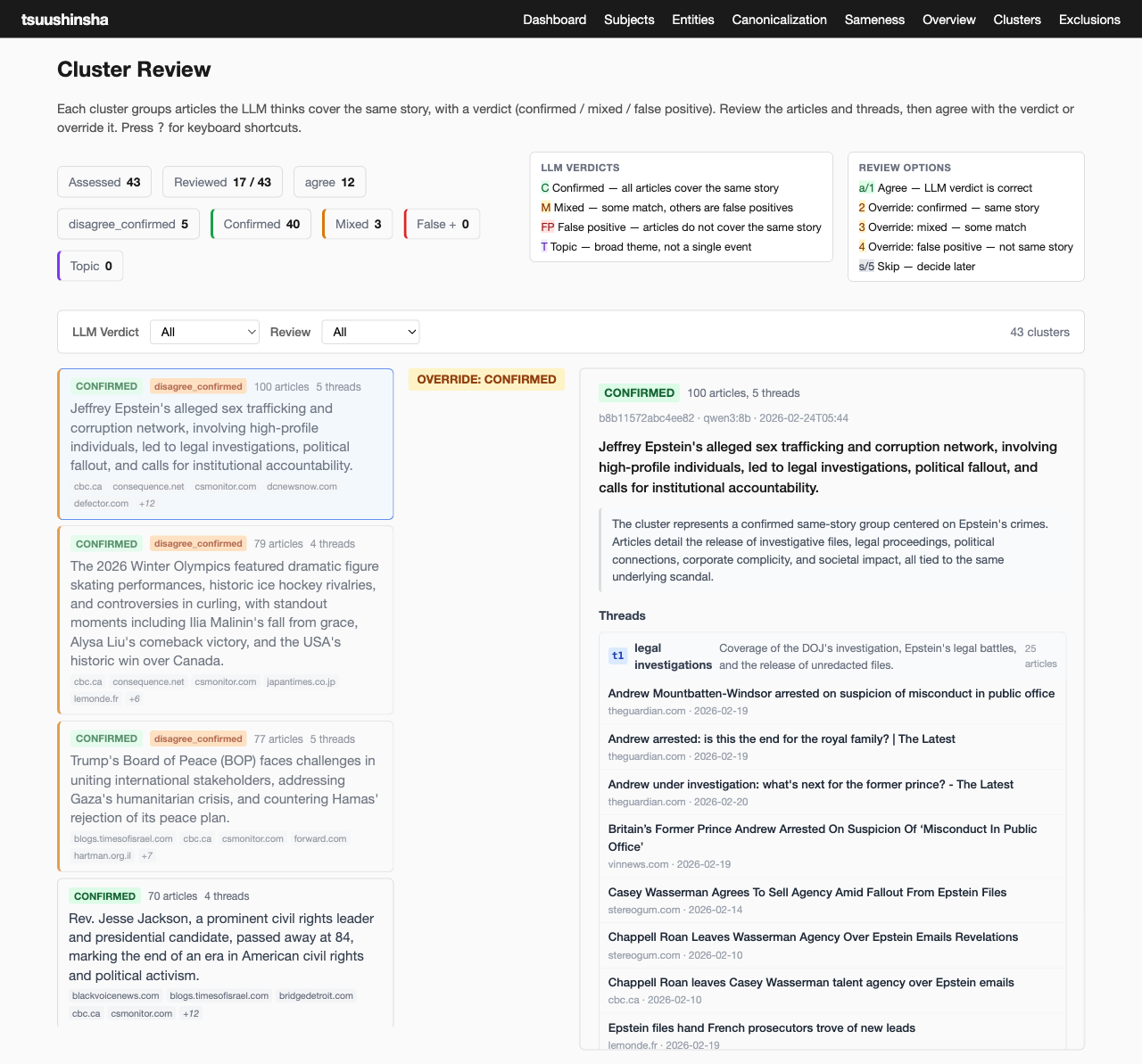
Current thinking
I miss having a good local paper. Our digital subscription will run out by this weekend. I am encouraged that I'm not far off from having something workable before long, encouraged that these experiments have started to show a hint that I can get to where I want to be, or at least closer. I've been putting off specifying a full UX plan while I figure out which of these experiments are going to fit together and how to administer them over time. And as I shift a little further toward confidence that I can cobble together enough tricks to produce something useful and meaningfully worth using, I've realized a few things I wasn't clear on at the start.
- I'm building something for me. I'll share the code once it adds up to something anybody other than me would want to look at, but it needs to fit my brain first and foremost.
- I thought I'd cobble together some extractors and relators and then have a UI. But the more of these evaluations I do, the more I realize that I'll probably keep refining these pieces as I go. Maybe not as intensively, but there will be new methods and models and I'll want to try new things. Experimentation with evaluation is a core function.
- There's a human-in-the-loop to some of the situations I've run into, where a local LLM can blow away a "traditional" model in performance but fails at the modest but not trivial scale I'm already at. But if you have a person look at one set of output and make judgements and choices and then put a briefer form of that output and choices into a local LLM, maybe you can get where you want to be.
- Maybe that personal mix of assessment and evaluation is not just something I want to engage in briefly during early experimentation. Maybe it's a core function of the system. I like doing this stuff. It helps me understand the material and how it arises in the world. I've been doing things like this for thirty years. Why stop?
Kagi News is very cool. It solves a clear set of my problems well, but creates others. Its summaries are succinct and efficient but I lose track of the voices of writers and the details and color that make for great writing. The Week does an admirable job of counterposing opinions from different postures, but that one-side-vs-the-other structure doesn't work for me.
I need something that's messy, that's local, that's weird, that doesn't fit into little boxes, that offers up something like a decent comics page, and all that takes some time. I'll let you know when I get a little further with it.